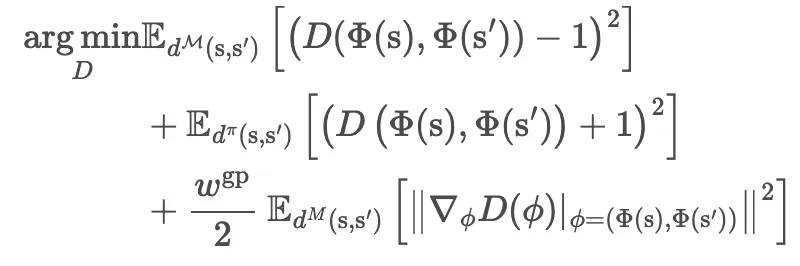amp
AMP: Adversarial Motion Priors for Stylized Physics-Based Character Control
项目地址:
代码地址:
方法
本论文采用了GAIL算法,虽然名字里带,但是实际上属于RL,而且是IRL(逆强化学习)的一种,巧妙地将IL和RL进行了结合。
逆强化学习IRL(Inverse Reinforcement Learning)则没有奖励,取而代之的是“环境互动+最大化从专家数据学到的奖励函数=最优Actor
逆GAIL(Generative Adversarial Imitation Learning)是使用GAN(Generative Adversarial Network)的IRL,即训练一个生成器 ,它从一个普通的分布逐渐生成与现有数据分布相似的分布。GAIL的数据集(参考运动)是。同样,我们希望我们的 Actor 能够模仿专家,即 Actor 产生的轨迹(的分布)与专家产生的轨迹(的分布)相似。GAN中的生成器和判别器这里不再赘述。reward是鼓励policy的行为和数据集里面的对尽可能像
AMP目标
本文的目标是训练一个agent,让其完成某个目标(Goal),同时保持某种风格(Style),其中风格由expert dataset或者demonstration dataset提供。本文混合了目标实现和模仿学习,其中模仿学习使用对抗性方式学习对给定风格的遵守,AMP中的A(Adversarial)就是对抗性。
奖励函数由两部分组成,一部分是目标奖励,另一部分是风格奖励,通过计算两者的加权和得到总奖励: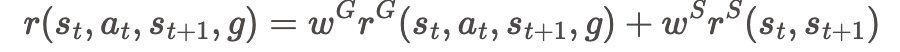
目标奖励
目标奖励函数描述到达目标的程度,其根据目标来设计
风格奖励
数据集可以是动捕数据,也可以从已经学会的Policy中得到。数据集只提供运动的风格,而不提供如何实现目标。风格奖励 描述遵守数据集中风格的程度,由运动先验(Motion Prior)进行判断,运动先验由GAN训练得到,经典的GAN Loss为:
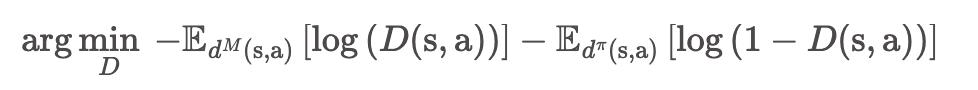
总体流程

- 梯度惩罚
GAN训练可能不稳定,使用梯度惩罚可以稳定训练